
VietFashion: Benchmarking Sketch–Text Composed Image Retrieval for Cultural Outfits
Published in ACM International Conference on Multimedia Retrieval (ICMR) 2026, 2026
Overview
This research project presents a novel pipeline combining SANA-ControlNet for high-fidelity sketch-conditioned image synthesis with Qwen2.5 3B Instruct for semantic caption generation. We address the critical challenge of obtaining diverse, high-quality training data for specialized domains like cultural garments. Our approach automates the entire triplet synthesis workflow, eliminating manual annotation and producing a large-scale, multi-modal dataset suitable for training and evaluation of composed image retrieval systems.

🎯 Motivation
Composed image retrieval (CIR) is the task of finding images in a database based on a query combining a reference image with text modifications. However, obtaining diverse, high-quality training data remains a significant bottleneck, particularly for specialized domains like cultural garments where data is scarce.
This project addresses this challenge by:
- Automating triplet generation from human-drawn sketch inputs, eliminating manual annotation requirements
- Leveraging SANA-ControlNet to synthesize photorealistic, culturally accurate garment images conditioned on spatial sketches
- Utilizing Qwen2.5 3B Instruct to generate consistent, attribute-rich captions starting with “A photo of…”
- Modeling real-world uncertainty via a Multi-Target Query Design ($1 \rightarrow 3$ mapping) that addresses false-negative supervision in composed retrieval
- Producing large-scale datasets (20,000 triplets) that enable training of robust CIR models for cultural garment applications
🔧 Technical Approach
The Synthesis Pipeline
Our pipeline follows a structured flow from abstract sketch input to aligned multi-modal triplets:
Key Components
- Attribute Sampling
- 11 curated categories from fashion archives: Fabric, Silhouette, Neckline, Sleeve Style, Color, Pattern, Embroidery, Fit, Length, Collar Type, and Ornamental Details
- Structured sampling ensures diverse, culturally authentic garment representations
- Maintains semantic consistency across triplets
- Image Synthesis (SANA-ControlNet)
- Generates high-quality garment images conditioned on sketch inputs and structured prompts
- Spatial control via ControlNet ensures sketch-image semantic alignment
- Produces diverse variations suitable for CIR training with photorealistic details
- Maintains cultural authenticity while adding photorealistic rendering
- Caption Generation (Qwen2.5 3B Instruct)
- Distills the attribute set into neutral, factual single-sentence captions
- All captions follow the format: “A photo of [garment description]…”
- Captures essential attributes (style, color, fit, cultural elements) comprehensively
- Produces descriptions that complement sketch-image pairs for robust triplet learning
- Triplet Formation & Multi-Target Query Design
- Aggregates Sketch (S), Caption (C), and Multiple Target Images (I₁, I₂, I₃) into final dataset entries
- One-to-Three mapping ($1 \rightarrow 3$) explicitly addresses false-negative supervision in CIR
- Provides multiple valid targets for each query, reflecting real-world retrieval scenarios
- Creates balanced datasets with diverse cultural garment categories
📊 Dataset
Dataset Statistics
- Total Triplets: 20,000 curated sketch-text-image triplets
- Human Sketches: 650 unique human-drawn query sketches
- Synthesized Images: 21,000 high-resolution fashion renderings (3 per triplet)
- Domain: Vietnamese Cultural Garments (Áo Dài and related traditional clothing)
- Format: JSON-based annotations with split support (train.json, val.json, test.json)
- Modalities: Sketch, Image, Text with explicit one-to-three mapping
Data Organization
- Triplet Format: Each entry contains (Sketch S, Caption C, Image₁ I₁, Image₂ I₂, Image₃ I₃)
- Splits: Training, validation, and test sets with balanced class distributions
- Image Quality: High-resolution photorealistic renderings suitable for deep learning models
📚 Benchmarks
The project includes implementations and evaluations of:
- Bi-Blip4CIR: Bidirectional BLIP-based composed image retrieval
- CLIP4Cir: CLIP-based composed image retrieval with fine-tuning
- Pic2Word: Vision-language model for composed retrieval
- SEARLE: Scalable end-to-end architecture for image retrieval
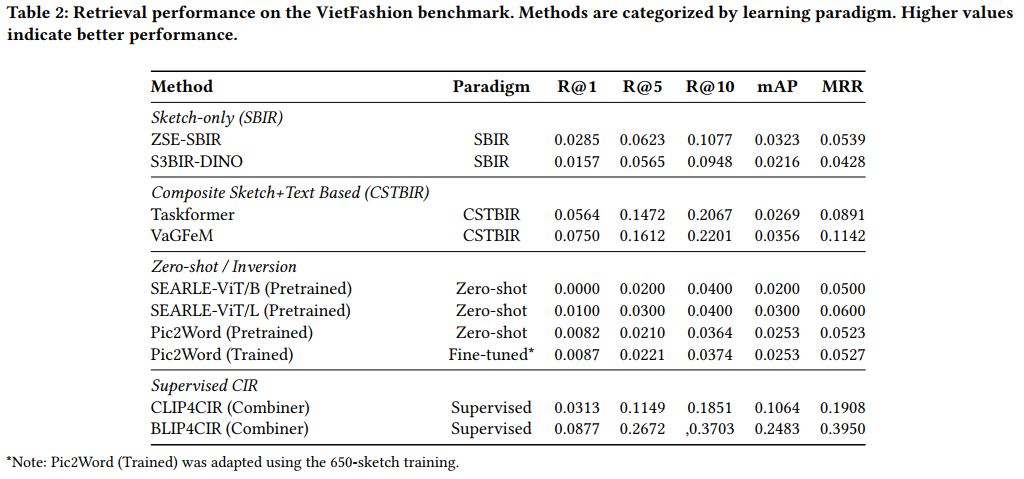
Result
Citation
@inproceedings{Cao2026ICMR,
title = {VietFashion: Benchmarking Sketch–Text Composed Image Retrieval for Cultural Outfits},
author = {Cao, Hoang-Nguyen and Bui, Le-Hoang and Vo, Dinh-Khoi and Tran, Minh-Triet and Le, Trung-Nghia},
booktitle = {International Conference on Multimedia Retrieval (ICMR)},
year = {2026},
note = {(B Rank)},
presentation = {},
project_page = {https://hng0303.github.io/VietFashion}
}