
RAGNews — Agentic LLM-Powered News Platform
Published:
Overview
RAGNews is a production-grade agentic news platform that ingests, indexes, and intelligently answers questions about news using a Retrieval-Augmented Generation (RAG) pipeline. The system uses a domain-fine-tuned LLM for summarization and a BERT-based classifier for sentiment analysis.
Pipeline Architecture
1. Agentic Routing
Built on FastAPI + LangChain, the system routes user queries through database-aware agents that autonomously decide between vector retrieval, keyword search, or direct answer paths.
2. Two-Stage Retrieval
- Stage 1 (Coarse): Vector search over Milvus for fast approximate nearest-neighbor retrieval.
- Stage 2 (Fine): Cross-encoder BGE-Reranker re-ranks top candidates for precision. This decoupling minimizes latency while maintaining quality.
3. LLM Fine-Tuning
- Fine-tuned Qwen2.5-1.5B using LoRA + Unsloth for domain-specific news summarization.
- Reduced training memory footprint by 60% vs. full fine-tuning.
- Integrated BERT-based sentiment classifier for financial news polarity tagging.
4. Production Serving
- Fine-tuned models served via vLLM for high-throughput inference.
- PostgreSQL for short-term and long-term conversation persistence.
- Streamlit UI for interactive sessions.
- Full Docker containerization for deployment.
Tech Stack
| Component | Technology |
|---|---|
| RAG Framework | LangChain |
| Vector DB | Milvus |
| Re-Ranking | BGE-Reranker |
| Fine-Tuning | LoRA + Unsloth |
| Inference | vLLM |
| Backend | FastAPI + PostgreSQL |
| Frontend | Streamlit |
| Infrastructure | Docker + Asyncio |
System Architecture
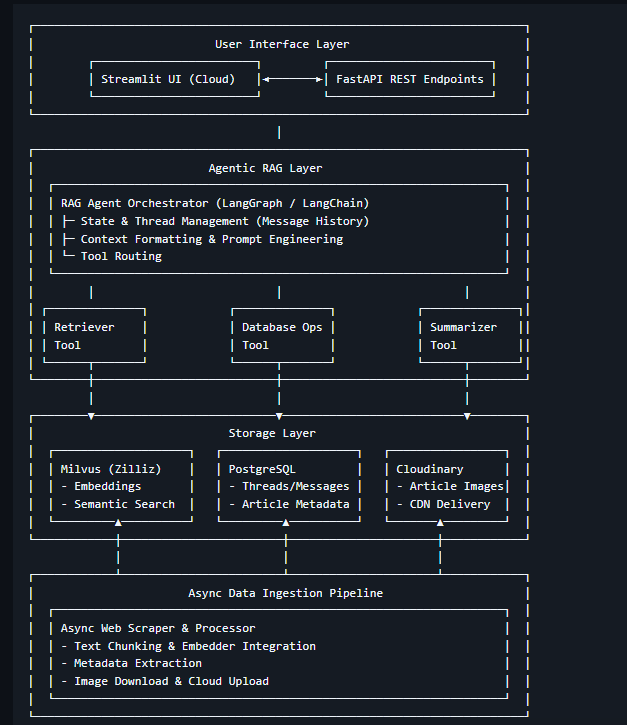
The two-stage retrieval pipeline:
- Milvus Vector Search: Fast approximate nearest-neighbor retrieval from indexed news corpus
- BGE-Reranker: Cross-encoder refinement for precision ranking
Demo
The platform provides:
- Interactive question-answering interface
- AI-powered news insights and sentiment analysis
- Real-time article retrieval and summarization
Key Results
- 60% reduction in GPU memory for fine-tuning via LoRA + Unsloth
- Asynchronous concurrent data ingestion pipeline handling multiple news feeds
- Low-latency retrieval via coarse–fine two-stage architecture